Capítulo 2 Introdução
Considerar a interpretabilidade é muito importante quando falamos de predições e classificações resultantes de um modelo. Buscar a interpretação de uma predição nos ajuda a entender como chegamos naquele resultado, quais características impactaram nele, além de nos ajudar a tomar decisões com mais responsabilidade e segurança.
Ao falarmos de interpretabilidade, uma possível abordagem é utilizar técnicas de modelagem que permitem entender diretamente como as variáveis explicativas se relacionam com a variável resposta: os Modelos Interpretáveis. Regressão Linear e Regressão Logística (Molnar 2019) são algumas dessas técnicas que podem ser consideradas interpretáveis, dependendo do nível de complexidade na combinação das suas variáveis, das regras e também do nível de domínio do assunto de quem está analisando-as (Doshi-Velez 2017).
](https://www.capgemini.com/gb-en/wp-content/uploads/sites/3/2020/03/Explanable-AI.jpg?w=960)
Figura 2.1: Fonte: Capgemini - Explainable AI- why is there a need to explain?
Entretanto, quando utilizamos modelos não interpretáveis, também conhecidos como Modelos Opacos ou “Caixa Preta”, não é possível entender diretamente a relação entre as variáveis explicativas e a variável resposta. Nesses modelos a predição pode ser resultado de um conjunto complexo de regras ou as relações não se apresentam de forma direta e linear, como em Florestas Aleatórias (Breiman 2001), as Máquinas de Vetores de Suporte (Shawe-Taylor and Cristianini 2000) (SVM, do termo em inglês Support Vector Machine), e as Redes Neurais Profundas (Liu et al. 2017).
Nesses casos não fica claro o impacto de cada variável e, como consequência, podemos ter uma série de problemas com variáveis que não deveriam ser relevantes e erroneamente são consideradas pelo modelo, seja por um viés de seleção das amostras ou por um viés histórico sócio-cultural que acaba refletindo na base de dados utilizada no treinamento do modelo. Esse cenário nos possibilita tomar decisões com base em predições enviesadas sem sequer saber disso, o que pode levar a repetição de padrões e processos discriminatórios que impactam diretamente na desigualdade entre indivíduos, como foi abordado por Cathy O’Neil em (O’Neil 2016).
A discussão sobre viés em algoritmos está permeada por muitas questões éticas e morais. Como apontado em (“Algoritmos de Inteligência Artificial E Vieses: Uma Reflexão Sobre ética E Justiça” 2020), essa discussão implica falar sobre questões como gênero, raça, idade, orientação afetiva-sexual, linguagem, cultura, deficiência, condição econômica, entre outros fatores e suas interseccionalidades.
Para ilustrar algumas dessas questões, trouxemos exemplos reais em que, por não terem considerado a etapa de interpretabilidade no processo de desenvolvimento do modelo, implica como resultado classificações incorretas e com impactos negativos, devido aos vieses na informações do treinamento do algoritmo.
2.1 Algoritmo de Contratação sexista
Segundo a agência Reuters (Reuters 2018), com a proposta de elevar o nível de tomada de decisão automática, a empresa Amazon desenvolveu internamente uma ferramenta experimental de contratação utilizando inteligência artificial para fornecer aos candidatos pontuações que variam de uma a cinco estrelas. Entretanto, a empresa percebeu que seu novo método não classificava os candidatos de forma neutra em termos de gênero.
Isso ocorreu porque, para classificar os candidatos, o modelo foi treinado utilizando a base histórica dos currículos enviados à empresa nos últimos 10 anos. Nessa base era refletida a dominância masculina que existe em toda a indústria de tecnologia.
](https://sloanreview.mit.edu/wp-content/uploads/2017/12/FR-Beck-Libert-Gender-Inequality-Equality-Issues-1200-300x300.jpg)
Figura 2.2: Fonte: MIT Sloan - Could AI Be the Cure for Workplace Gender Inequality?
De acordo com a reportagem da The Guardian (Guardian 2018), cerca de 55% dos gerentes de recursos humanos dos EUA disseram que a inteligência artificial seria uma parte regular de seu trabalho nos próximos cinco anos, segundo uma pesquisa de 2017 realizada pela empresa de software de talentos CareerBuilder.
Esse tipo de experimento que a (Reuters 2018) relatou, é um exemplo sobre as implicações éticas que um modelo pode ter e o quão importante e urgente é a preocupação de interpretar o modelo.
2.2 Algoritmo de classificação de imagens
Em (Lapuschkin et al. 2019) foi estudado um exemplo em que o algoritmo de aprendizado de máquina encontrou uma característica curiosa nas imagens para classificá-las. O objetivo era classificação entre cavalo, pessoa, trem ou carro. Entretanto, para classificar como cavalo o algoritmo considera como área relevante a marca d’água do fotógrafo que estava na base de treinamento do modelo. Isso justifica porque, na base de teste, uma imagem de carro que contém a marca d’água é classificada como cavalo, como visto na figura abaixo.
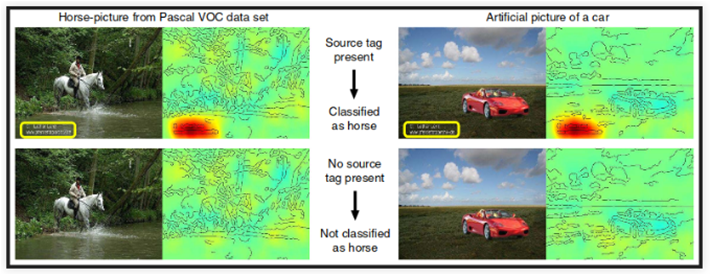
Figura 2.3: Fonte:
Nesse caso, a marca d’água do fotógrafo na base de treinamento atrapalhou a classificação, e quando observamos na imagem quais áreas foram mais relevantes para aquela rotulação como cavalo encontramos a resposta do viés do algoritmo.
References
“Algoritmos de Inteligência Artificial E Vieses: Uma Reflexão Sobre ética E Justiça.” 2020. https://www.programaria.org/algoritmos-de-inteligencia-artificial-e-vieses-uma-reflexao-sobre-etica-e-justica/.
Breiman, Leo. 2001. “Random Forests.” Machine Learning 45 (1). Springer: 5–32.
Doshi-Velez, e Been Kim, Finale. 2017. “Towards a rigorous science of interpretable machine learning.” arXiv Preprints arXiv:1702.08608.
Guardian, The. 2018. “Amazon ditched AI recruiting tool that favored men for technical jobs.” \url{https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine}.
Lapuschkin, S., S. Waldchen, A. Binder, G. Montavon, W. Samek, and K. Muller. 2019. “Unmasking Clever Hans Predictors and Assessing What Machines Really Learn.” Nature Communications.
Liu, Weibo, Zidong Wang, Xiaohui Liu, Nianyin Zeng, Yurong Liu, and Fuad E Alsaadi. 2017. “A Survey of Deep Neural Network Architectures and Their Applications.” Neurocomputing 234. Elsevier: 11–26.
Molnar, Christoph. 2019. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. Online.
O’Neil, Cathy. 2016. Weapons of Math Destruction. United States: Crown Books.
Reuters. 2018. “Amazon scraps secret AI recruiting tool that showed bias against women.” \url{https://www.reuters.com/article/us-amazon-com-jobs-automation-insight}.
Shawe-Taylor, John, and Nello Cristianini. 2000. “Support Vector Machines.” An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. Cambridge University Press, 93–112.